Топик для комментариев и кратких обсуждений из "Ленты новостей". Убедительная просьба для полновесных дискуссий заводить отдельные топики.
Предыдущая часть темы: Обсуждение - Математика и программирование




Амальгама |
Привет, Гость! Войдите или зарегистрируйтесь.
Вы здесь » Амальгама » Математика и программирование » Обсуждение - Математика и программирование #2

Топик для комментариев и кратких обсуждений из "Ленты новостей". Убедительная просьба для полновесных дискуссий заводить отдельные топики.
Предыдущая часть темы: Обсуждение - Математика и программирование

Я так понимаю, что если байт памяти - пустой, туда можно что-то записать?
На самом деле он не пустой, там будет случайная последовательность,
образовавшаяся при включении компьютера...Поэтому, память, выделенную под какие-либо данные сначала обнуляют,
то есть записывают в ячейки, выделенные под какую-то переменную - нули.
И тлгда этот байт памяти уже не пустой, в нем хранится значение переменной,
равное нулю.
Вот объяcни нахера ты эту пургу несешь?

Это неверно. Сначала растет, а потом падает за счет совпадений и исключений дубликатов.
Даже спорить не буду. У тебя только сугубо теоретические представления о своей таблице, а я ее реально делал. Ты думаешь, что она работает так, а я знаю, что работает она совсем не так. Сделай сам работающую таблицу, тогда обсудим.
Одна из важных задач, решаемых в программировании,— это обеспечение быстрого (прямого) доступа к данным по некоему коду (индексу, адресу)
Сдается, что у тебя алгоритм не быстрого поиска по индексу, а быстрый поиск самого индекса.
А для поиска самих данных, как говорит Шарпер, "есть обычный код". 
Проблема дубликатов не решена никак и представляет собой традиционный геморрой
Я так понимаю, что здесь вопрос скорее обмена одного геморроя на другой.
Там строковая обработка, а не битовая.
Без разницы. Принцип то тот же. Посимвольная обработка цепочки символов, начиная с первого.
Ее аолгоритм "протаптывания/зарастанияя" решает
В таком подходе с простым посимвольным анализом не решает. Если первый символ неверный, то система не сможет сгенерировать ни одной правильной цепочки, потому что она будет рассматривать слова, начинающиеся не с той буквы. То есть никаким протаптыванием слово Царпер не станет Шарпером, по той простой причине, что она будет генерировать подсказки только начинающиеся на букву Ц, а слово Шарпер, как назло, к ним не относится.
Будешь Царь Петр вместо Шарпера, тоже неплохо 
Сделай сам работающую таблицу, тогда обсудим.
Я ее делал в 2010 году. Тогда этот парадокс и выяснился. Но он очевиден и на примере натурального ряда 32-разрядных чисел.
В стандартном представлении одни только незначащие нули занимают море памяти, не говоря уже о совпадающих частях. Впрочем и это неважно при нынешних технологиях.
Сдается, что у тебя алгоритм не быстрого поиска по индексу, а быстрый поиск самого индекса.
А для поиска самих данных, как говорит Шарпер, "есть обычный код".
Не для поиска, а для хранения. Для поиска как раз вот этот комплементарный код. И получится аналог "ДНК" с прямым и комплементарныи кодом. 
Я так понимаю, что здесь вопрос скорее обмена одного геморроя на другой.
А вот это проверяется
В таком подходе с простым посимвольным анализом не реша
Это вообще другая тема. Потом. Если захотите.

Это стандартная двоичка 0000-00FF.
И там есть пустой байт?
И там есть пустой байт?
0000-00FF.
В стандартном представлении одни только незначащие нули занимают море памяти, не говоря уже о совпадающих частях
Я уже не помню подробностей, вроде бы твоей системе вся память уходит на адреса. Незначащие нули может и не будут занимать память, ее гораздо лучше будут занимать адреса всех этих нулей. Опять получаем вместо одного бита байт, и возможно не один, а несколько.
И она запредельно геморна в плане корректировок и удаления записей. Чтобы поменять, добавить или удалить один символ нужно перетрахивать всю таблицу целиком.
Отредактировано Zagar (2023-07-08 13:20:05)
0000-00FF.
Вижу шестнадцатеричные цифры, нули и эфки.
Пустых байтов - не вижу! 
Отредактировано Лукомор (2023-07-08 13:28:03)
Я уже не помню подробностей, вроде бы твоей системе вся память уходит на адреса. Незначащие нули может и не будут занимать память, ее гораздо лучше будут занимать адреса всех этих нулей. Опять получаем вместо одного бита байт, и возможно не один, а несколько.
Нет не так. Совпадающие части будут представлены только один раз, а значит все незначащие нули, кроме первого будут накладываться друг на друга. И не только нули, а вообще совпадабщие
И она запредельно геморна в плане корректировок и удаления записе
Это опять другая тема. Там не один вариант усложнения структуры
Пустых байтов - не вижу!
А они есть, и ты сам пишешь -
Вижу шестнадцатеричные цифры, нули и эфки.
А они есть, и ты сам пишешь -
Да где они есть-то,
если я пишу, что вижу байты памяти заполненные нулями и единицами,
и не вижу байтов пустых, незаполненных ничем, или заполненных всякой билибердой
от фонаря при включении компьютера..
Именно поэтому, объявив массив, и выделив для него память, эту память в обязательном
порядке заполняют нулями, чтобы не было пустых ячеек, содержащих произвольные
значения.
Отредактировано Лукомор (2023-07-08 18:17:44)
не вижу байтов пустых, незаполненных ничем, или заполненных всякой билибердой
от фонаря при включении компьютера
Ты еще на атомный уровень залезь! Договорились, что обсуждаем на логическом уровне. А на нем пусто=нуль
А на нем пусто=нуль
Или пусто=единицв,.
это без разницы...
Но так все равно не бывает.
Обычно на уровне логики - присутствуют сигналы двух уровней ,
высокий - ноль, низкий - единица.
Отредактировано Лукомор (2023-07-08 19:40:50)
Обычно на уровне логики
рассматриваются только символы
символ "ноль" и отсутствие символа, это несколько разные вещи.
Если ячейки памяти пустые, свободные, и не содержат никакой информации,
туда можно какую-то информацию записать.
А если в ячейки памяти заполнены нулями, туда уже ничего не запишешь,
не испортив хранящуюся там информацию.
символ "ноль" и отсутствие символа, это несколько разные вещи.
Точно! И еще нельзя говорить дырка, надо - отверстие, ибо не по феншую! И начхать, что символ ноль это символ отсутствия величины. Главное найти повод. Ты случаем гаишником не работал? 
Если ячейки памяти пустые, свободные, и не содержат никакой информации
На логическом уровне все разряды строго 0 или 1.
На логическом уровне все разряды строго 0 или 1.
Да.
Даже когда в память не записано никакой информации.
еще нельзя говорить дырка, надо - отверстие,
А также не по феншую говорить "наушники", ибо правильное название
"головные телефоны".
И начхать, что символ ноль это символ отсутствия величины.
А символ единица - это символ чего?
а значит все незначащие нули, кроме первого будут накладываться друг на друга
То есть 11 и 10000001 - это будет одно и то же число?
В реальности у тебя в каждой точке последовательности идет ветвление, в каждой такой ячейке нужно хранить два адреса (на случай продолжения нулем или единицей), то есть два байта. Ветвление будет идти со скоростью 2^n, на 8-символьную последовательность нужно уже 510 байтов, вместо одного байта, если цепочку хранить в обычном виде. Для трехбуквенного (24-битного) слова счет ячеек пойдет на десятки мегабайтов.
В сторону уменьшения этого объема будет работать то, что не все последовательности будут реализовываться. Но сильно тут радоваться вряд ли стоит. В стандартной странице ASCII с русским и английским алфавитом заняты практически все позиции, ну допустим часть служебных символов можно убрать, но все равно даже самое радикальное сокращение не даст даже двукратного сокращения. Ну даже пусть в два раза и будет не 510, а 250 байт на букву - все равно на два порядка больше, чем при обычной записи.
Больший эффект может быть получен на уровне слов, но там уже ветвление от буквы к буквы будет идти со скоростью 256^n. Даже если в виде слова реализуется один из миллиона наборов букв, то для записи слова Шарпер нужны будут гигабайты памяти. И удаление дубликатов не поможет. В слове коловорот нельзя оставить одну о и исключить три остальных о. Потому как выходная адресация у каждой из них разная, это символы с разными свойствами, они не идентичны.
Это опять другая тема.
Да не совсем. Мы обсуждаем реальную работоспособность твоей таблицы, это важный момент в этой дискуссии.
вижу байты памяти заполненные нулями и единицами,
и не вижу байтов пустых, незаполненных ничем, или заполненных всякой билибердой
от фонаря при включении компьютера
Я про это писал. Паузы как отсутствие и 0 и 1 нужны. Иначе непонятно как ставить пробелы между словами.
А символ единица - это символ чего?
Блиииин! Это символ наименьшего числа!
Я требую пытку Лукомором внести в список запрещенных!

символ наименьшего числа!
-∞ ?
То есть 11 и 10000001 - это будет одно и то же число?
Нет, конечно. Они ж отличаются во втором знаке.
В реальности у тебя в каждой точке последовательности идет ветвление, в каждой такой ячейке нужно хранить два адреса (на случай продолжения нулем или единицей), то есть два байта. Ветвление будет идти со скоростью 2^n, на 8-символьную последовательность нужно уже 510 байтов, вместо одного байта, если цепочку хранить в обычном виде. Для трехбуквенного (24-битного) слова счет ячеек пойдет на десятки мегабайтов.
1 И что страшного в десятках мегабайтов, если можно при необходимости реализовать терабайты со страничной организацией? Снова напомню про поля обогатительных центрифуг, когда "очевидная расточительность" обернулась чрезвычайной эффективностью. Проявление золотого правила механики - проигрываешь в расстоянии- выигрываешь в силе/производительности. Так что не вижу проблем в требуемом объеме, при том, что вся память однородная и не нужно гемороиться со спецустройствами ассоциативного доступа или изобретать средства против коллизий хеширования. Еще напомню, что изобюилиеп памяти привело к изменению программирования - циклы стали заменять повторяющимися коммандами. И иакая расточительность только приветствукется. И это все даже без учета наложений.
2 А с наложениями, еще интереснее. Вот картинка. Обратите внимание, что все числа начинаются с меньших разрядов 0 или 1 и накладываются вплоть до точки ветвления. Так что каждое следующее число ряда будет давать прирост всего на два адресных слова.
Больший эффект может быть получен на уровне слов, но там уже ветвление от буквы к буквы будет идти со скоростью 256^n
Совсем не так! Каждая словоформа, обработанная таким способом будет заканчиваться в уникальной адресной позиции, которую можно брать в качестве кода этой словоформы. Более того, таким же кодом можно кодировать регулярные словосочетания. И тогда возникает вопрос, а не будет ли такая кодировка с длиной слов равной адресу компактнее стандартной? Я уверен, что таки будет, т.к. иероглифическая запись короче алфавитной
Больший эффект может быть получен на уровне слов, но там уже ветвление от буквы к буквы будет идти со скоростью 256^n
Как видите, все не так
Да не совсем. Мы обсуждаем реальную работоспособность твоей таблицы, это важный момент в этой дискуссии.
Давайте попозже
-∞ ?
Как и ноль это не натуральное число
Блиииин! Это символ наименьшего числа!
Наименьшее число - это минус бесконечность...
Наименьшее число - это минус бесконечность...
Как и ноль это не натуральное число
С натуральными все понятно.
Но есть еще дроби, то-есть рациональные числа, есть иррациональные, комплексные,
и, наконец, кватернионы, столь популярные в механике.
Их тоже надо как-то кодировать?
Обратите внимание, что все числа начинаются с меньших разрядов
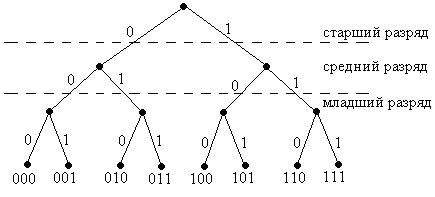
Отредактировано Лукомор (2023-07-09 13:29:17)
Нет, конечно. Они ж отличаются во втором знаке.
Отлично, а что насчет 101 и 10000001? Второй знак тот же, дальше ничего, пустота, все нули можно собрать в один, разницы никакой.
И что страшного в десятках мегабайтов, если можно при необходимости реализовать терабайты со страничной организацией?
Ну просто для работы Амальгамы потребуются суперкомпьютеры, а так ничего.
Снова напомню про поля обогатительных центрифуг, когда "очевидная расточительность" обернулась чрезвычайной эффективностью.
Да ладно. Есть тупо степень обогащения на каждой центрифуге, можно посчитать, сколько нужно последовательных стадий обогащения, чтобы достичь нужного уровня. Есть предельная мощность центрифуги, зная общую требуемую мощность производства можно легко посчитать количество параллельных линий. Умножаем одно на другое и еще немного на резерв оставляем, получаем нужное число центрифуг. В чем тут очевидная расточительность? Был бы менее расточительный вариант, его бы и использовали. И что еще за чрезвычайная эффективность? Там нет никакого синергизма от того, что центрифуг много, вот если бы эффективность работы каждой центрифуги возрастала бы от роста их числа, но нет, там простая аддитивность, никаких чудес.
А с наложениями, еще интереснее.
Чего тут интересного? Всё по теории: на 3 двоичных знака уже 14 байтовых адресов, на 8 двоичных знаков (1 байт) нужно будет 510 байтовых адресов. Всё как я описывал.
Каждая словоформа, обработанная таким способом будет заканчиваться в уникальной адресной позиции, которую можно брать в качестве кода этой словоформы.
Если тебе нужен уникальный адрес, соответствующий каждому слову, то просто возьми орфографический словарь, пронумеруй все слова и не морочь людям голову.
И тогда возникает вопрос, а не будет ли такая кодировка с длиной слов равной адресу компактнее стандартной?
Сам кодировка будет иметь длину в один адрес, но если тебе нужно знать слово, которое она кодирует (а иначе в этой системе нет никакого смысла), то нужна вся цепочка адресов. То есть для каждого символа надо хранить не только исходящий адрес, но и входящий, чтобы по этой цепочке можно было пройти в обратном направлении и собрать все буквы.
Как видите, все не так
Нет, не вижу.
Отлично, а что насчет 101 и 10000001? Второй знак тот же, дальше ничего, пустота, все нули можно собрать в один, разницы никакой.
Вы картинку видите? 101 там есть, а 10000001 пойдет по ветке от 100 и далее по нулевым, т.е. совпадет с веткой числа 1000000
Ну просто для работы Амальгамы потребуются суперкомпьютеры, а так ничего.
Нет, конечно. Микро sd уже террабайтные.
там простая аддитивность, никаких чудес.
И я о том же.
Чего тут интересного? Всё по теории: на 3 двоичных знака уже 14 байтовых адресов, на 8 двоичных знаков (1 байт) нужно будет 510 байтовых адресов. Всё как я описывал.
В компьютерах используются 32 и 64 разрядные слова и эти 3битовые числа будут содержать от 3 до 7 байтов незначаших нулей или медленно изменяюшимися значениями в старших разрядах. А адресовать их можно не полным адресом, а смещением.
Если тебе нужен уникальный адрес, соответствующий каждому слову, то просто возьми орфографический словарь, пронумеруй все слова и не морочь людям голову.
Это не работает для регулярных словосочетаний и тем более не работает для нетекстовых выражений
Сам кодировка будет иметь длину в один адрес, но если тебе нужно знать слово, которое она кодирует (а иначе в этой системе нет никакого смысла), то нужна вся цепочка адресов. То есть для каждого символа надо хранить не только исходящий адрес, но и входящий, чтобы по этой цепочке можно было пройти в обратном направлении и собрать все буквы
Для этого есть стандартный код. Как уже говорил выще, получается нечто вроде ДНК кода с прямой и комплементарной последовательностями.
Вы здесь » Амальгама » Математика и программирование » Обсуждение - Математика и программирование #2

