.
Отредактировано Шарпер (2021-12-04 22:51:04)




Амальгама |
Привет, Гость! Войдите или зарегистрируйтесь.
Вы здесь » Амальгама » Reductor Sapiens » Новая теория памяти – прорыв или утопия? #2

.
Отредактировано Шарпер (2021-12-04 22:51:04)
Но почему компьютер более приспособлен для номера в таблице символов, представленного в двоичке, чем к самому символу, представленному в двоичке?
Ой ты божечки! Опять за рыбу гроши! Скажи мне что ты знаешь о разрядности и форматах данных?

Скажи мне что ты знаешь о разрядности и форматах данных?
При чем тут разрядность и форматы данных, хранящихся в памяти, когда речь до сих пор шла об адресах ячеек памяти.

Нет. Полнотекстовый поиск побайтный, числовой - пословный это раз, а два и главное это объем поискового массива на порядки меньше
Не морочьте голову, товарищ. У тебя в поиске будут 33 русские буквы (+ столько же заглавных), 26 английских букв (+ столько же заглавных), 10 цифр (тут единственное отличие от букв, что заглавных цифр не бывает), а также всякие служебные символы (знаки препинания, всякая хрень типа # и &, а также, конечно, $). Итого, порядка 140 обязательных символов, это минимум без которого на поиск и замахиваться нечего. Какие там 33, пословный поиск и экономия памяти, сказки...
Работает. Я просто предложил Вам варианты, с моей точки зрения для текстов ненужные, но которые могут пригодиться в случае видеосигналов
Какие на хрен видеосигналы? У тебя это на словах из 33 букв уже не работает.
Кстати, видеосигналы тоже будем делить на осмысленные/используемые и прочие или как? Что там в видеосигналах с приставками и суффиксами?
Массу коротких можно использовать непосредственно, как адреса, а длинные в качестве данных. Есть море хитростей преодоления подобных трулностей и мне более всего нравится массив объемом в миллион, а то и много меньше значений
Ну то есть без ручного управления лично Шарпером этот алгоритм работать не будет в принципе.
Два однокоренных слова и что?
И то, что грош цена твоим разговорам про отсечение бессмысленных и суффиксов.
поскольку в машинном виде так или иначе будет двоичка
В машинном виде не двоичка, а электроны бегают.
Не морочьте голову, товарищ. У тебя в поиске будут 33 русские буквы (+ столько же заглавных), 26 английских букв (+ столько же заглавных), 10 цифр (тут единственное отличие от букв, что заглавных цифр не бывает), а также всякие служебные символы (знаки препинания, всякая хрень типа # и &, а также, конечно, $). Итого, порядка 140 обязательных символов, это минимум без которого на поиск и замахиваться нечего. Какие там 33, пословный поиск и экономия памяти, сказки...
Не в поиске, а при вводе ключа, а далее будет использоваться вычисленное значение либо аналогичное хешкоду, либо в виде прямого адреса. А ввод и преобразование введенного ключа есть и в стандартном поиске. Про экономию памяти у нас вообще речи не было. Был недостаток в виде расточительного ее использованию под таблицы, который в процессе обсуждения был устранен.
Какие на хрен видеосигналы? У тебя это на словах из 33 букв уже не работает.
С этого места подробнее, а то непонятно почему претензия к массиву с миллионом адресов введенному вместо индексов выдается за неработоспособность?
Ну то есть без ручного управления лично Шарпером этот алгоритм работать не будет в принципе.
Я вообще не понимаю о каком ручном управлении Вы говорите. Хотите сказать, что алгоритм должен самозародиться или он все-же должен программистами быть реализован?
И то, что грош цена твоим разговорам про отсечение бессмысленных и суффиксов.
Ну, Вы уж извините, что без разрешения, но так работают все редакторы умеющие ставить переносы. Так что предъявите претензии разработчикам
В машинном виде не двоичка, а электроны бегают.
С биологической точки зрения человек вообще кусок протоплазмы набитый бактериями в башке которого бегают биоэлектричекие потенциалы. Но любят человеков не за это
При чем тут разрядность и форматы данных, хранящихся в памяти, когда речь до сих пор шла об адресах ячеек памяти.
Вот именно! Так что можешь уже и не отвечать. Помнишь с чего сыр-бор начался? С вопроса ко мне что у тебя есть реального к "коммуитатору". Ну вот, пришли к признанию годности предложения. А теперь понеслись вопросы к тому что на этом способе можно сделать. А это уже вне рамок поставленного вопроса Тут пусть разрабоитчики думают, а я все - Элджернон. Мозги уже плохо работают
Тут пусть разрабоитчики думают
Так мы и есть разработчики, не?
И хрена ли тут думать?
Вот таблица, реализующая концепт шарперозависимой памяти.
В ней уже сохранены все возможные и невозможные словоформы, без ограничения на длину, в смысле на количество букв в слове..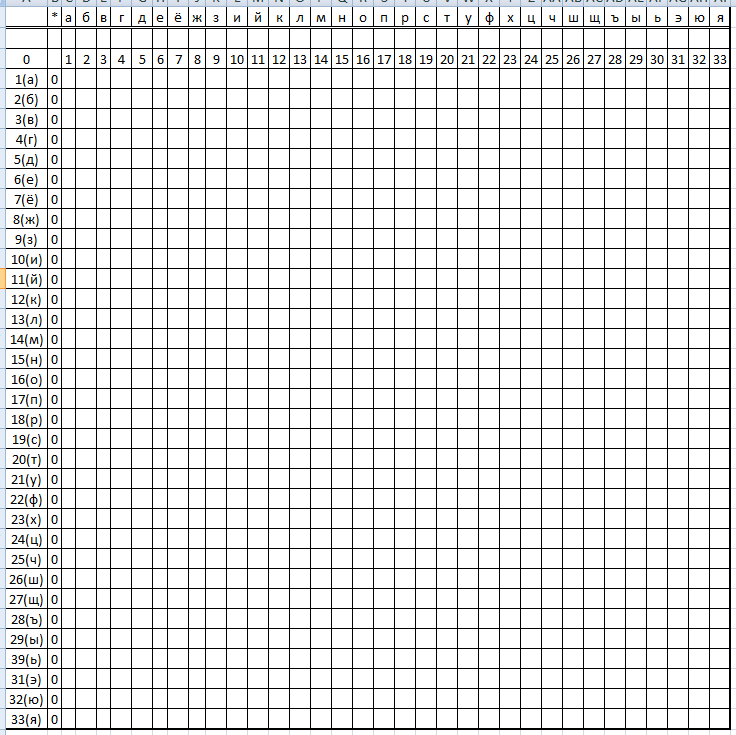
Все в точности соответствует техзаданию...
Отредактировано Лукомор (2022-01-23 04:37:29)
Вот таблица, реализующая концепт шарперозависимой памяти.
В ней уже сохранены все возможные и невозможные словоформы, без ограничения на длину, в смысле на количество букв в слове..
1 Как оказалось, таблица не нужна поскольку заменяется вычислением
2 Нет, мы не разработчики. Ничем реальным это не закончится - время вышло. Была надежда, что хоть кто-то подхватит, но судя по всему никто.
Не морочьте голову, товарищ. У тебя в поиске будут 33 русские буквы (+ столько же заглавных), 26 английских букв (+ столько же заглавных), 10 цифр (тут единственное отличие от букв, что заглавных цифр не бывает), а также всякие служебные символы (знаки препинания, всякая хрень типа # и &, а также, конечно, $). Итого, порядка 140 обязательных символов, это минимум без которого на поиск и замахиваться нечего. Какие там 33, пословный поиск и экономия памяти, сказки...
Вот чиста интересно, а к 256 битным хешам с коллизиями у Вас претензий почему нет? Которые тоже функции данных, но вовсе не уникальные. Чем предложенный способ преобразования текстов в уникальный длинный код отличается от хеширования с получением кода тоже длинного но неуникального?
1 Как оказалось, таблица не нужна поскольку заменяется вычислением
Как оказалось, для моей новой таблицы формула несколько другая.
И она решеает все проблемы с нехваткой памяти.
2 Нет, мы не разработчики.
Ну почему же? Я еще надеюсь довести до окончательной реализации свой алгоритм применительно к мини-играм.

а к 256 битным хешам с коллизиями у Вас претензий почему нет?
Они, вроде как, ничего плохого не делали. Денег в долг не брали, по телефону не угрожали. Почему должны быть к ним претензии?
Не в поиске, а при вводе ключа
Это не про алгоритм, а про общую формулировку постановки задачи поиска. Любой алгоритм должен строиться на основе понимания допустимого набора символов. Это не про твою формулу, а про ошибочность тезиса, что хватит 33 буквы.
С этого места подробнее, а то непонятно почему претензия к массиву с миллионом адресов введенному вместо индексов выдается за неработоспособность?
А вот с этого места нужен точный ответ какой вариант мы рассматриваем. Если ты просто запоминаешь вычисленные значения в обычной адресной памяти, то это одно. А если считаешь, что вычисленное значение соответствует уникальному номеру ячейки, то это совсем другое. Так что определись - ты про какой вариант из этих двух сейчас излагаешь? Или про какой-то третий?
Ну, Вы уж извините, что без разрешения, но так работают все редакторы умеющие ставить переносы.
То есть ты предлагаешь к поисковику прикрутить вордовский спелчекер со словарями и блоком анализа текстов? Охренеть быстрый и эффективный поиск будет, ага. 
И главное, как ты сможешь сократить обьем требуемой памяти, если будешь точно знать как правильно расставить переносы в слове DoctorLector? 
Вот чиста интересно, а к 256 битным хешам с коллизиями у Вас претензий почему нет?
Да я и слов то таких не знаю, какие там претензии...
Помнится, кто-то уходил макетировать глобус...

Помнится, кто-то уходил макетировать глобус...
Да нет здесь настоящих ценителей географии, эхх...
Они, вроде как, ничего плохого не делали. Денег в долг не брали, по телефону не угрожали. Почему должны быть к ним претензии?
А предлагается ничто иное, как вариант хэша с несколько большими возможностями, чем у трдиционного
нет здесь настоящих ценителей географии, эхх...
Я ценитель. Видимо, потому что четвёрка по географии.
ошибочность тезиса, что хватит 33 буквы.
Ага. Особенно если тезис на ходу подменить
А вот с этого места нужен точный ответ какой вариант мы рассматриваем. Если ты просто запоминаешь вычисленные значения в обычной адресной памяти, то это одно. А если считаешь, что вычисленное значение соответствует уникальному номеру ячейки, то это совсем другое. Так что определись - ты про какой вариант из этих двух сейчас излагаешь? Или про какой-то трети
Вообще-то я считал, что рассматриваю вариант вычисления порядкового номера комбинации заданной словом, о чем прямо заявил -
Короче вроде так для 33^n... из под гнета
Вычисляем номер комбинации иди элемента массива
КС+33*(ПС+33*(ПС+(33*НС)))где КС - номер конечного символа в слове, ПС - предыдущий символ, НС - начальный, 33 - размер
Отредактировано Шарпер (2022-01-21 15:25:33)
В отличие от табличного варианта, в котором исключаются пустые строки, вычислительный не тратит память, но приврдит к длинным числам, а их использовать можно различными способами, которые я и предложил на выбор, после того, как Вам почему-то не понравился служебный массмв крайне малого объемы по сравнению с традиционными индексными. Почему замена одних массивов на меньшее количество других Вам не нравится сие есть загадочная загадка при условии, что к традиционным хэшам у Вас никаких претензий нет, а к предлагаемым вдруг есть.
То есть ты предлагаешь к поисковику прикрутить вордовский спелчекер со словарями и блоком анализа текстов? Охренеть быстрый и эффективный поиск будет, ага
Не я предлагаю, а давно сделано все и применяется, но претензия почему-то ко мне. Почему?
Да я и слов то таких не знаю, какие там претензии...
Как это не знаете, если Вы мне ютубовский хэшкод ролика предлагали?
вариант хэша с несколько большими возможностями, чем у трдиционного
Я сторонник традиционного кеширования.
кеширования
Которое ни разу не хеширование
Я сторонник традиционного
Хеш-таблицей называется структура данных, позволяющая хранить пары вида «ключ» — «хеш-код» и поддерживающая операции поиска, вставки и удаления элемента. Хеш-таблицы применяются с целью ускорения поиска, например, при записи текстовых полей в базе данных может рассчитываться их хеш-код, и данные могут помещаться в раздел, соответствующий этому хеш-коду. Тогда при поиске данных надо будет сначала вычислить хеш-код текста, и сразу станет известно, в каком разделе их надо искать. То есть искать надо будет не по всей базе, а только по одному её разделу, а это ускоряет поиск.
Бытовым аналогом хеширования в данном случае может служить размещение слов в словаре в алфавитном порядке. Первая буква слова является его хеш-кодом, и при поиске просматривается не весь словарь, а только слова, начинающиеся на нужную букву.
Особенно если тезис на ходу подменить
Ничего я не менял, я не первый раз про это пишу. Немного не в тему разве что. Просто у вас с Лукомором была дискуссия сколько нужно символов - 33 или 256, вот я в рамках этой дискуссии и поделился своей оценкой.
ообще-то я считал, что рассматриваю вариант вычисления порядкового номера комбинации заданной словом
Вопрос (уже заданный раньше) не в этом. Посчитать то можно, вопрос что дальше с результатом расчета делать и зачем он нужен. Ответа пока что не вижу.
Вам почему-то не понравился служебный массмв крайне малого объемы по сравнению с традиционными индексными
А где там крайне малый объем? При перекодировании букв в цифры количество символов в слове вырастает, соответственно растет обьем требуемой памяти. Одна только буква "ш" в слове "Шарпер" в числовом виде потребует 10-значного числа вместо собственно одного символа. И это при 33-буквенном алфавите, а уж если взять 140 или 256 или слово подлиннее, так и того хуже.
Не я предлагаю, а давно сделано все и применяется, но претензия почему-то ко мне. Почему?
В элементарном поиске символьных последовательностей (который мы и обсуждаем) это не применяется. Это навороты на совсем других уровнях.
Как это не знаете, если Вы мне ютубовский хэшкод ролика предлагали
А, так это просто символьное обозначение ролика? Нет никаких претензий, с чего бы? Это у тебя были, а не у меня. Ты их отказывался считать обьектом поиска на том основании, что это бессмысленные сочетания символов, они рушили твой тезис про ограниченный обьем используемых слов.
с Лукомором была дискуссия сколько нужно символов - 33 или 256
Не мудрено, я с Лукомором досчитал до 512... 
Немного не в тему разве что
Вот именно. Я то все время ориентируюсь на хеширование с преобразованием текста в уникальное длинное целое двоичное число, которое для использования в HTML, переводится в цепочку символов. Эти хеши хранятся в таблице. Вот, повторюсь -
Хеш-таблицей называется структура данных, позволяющая хранить пары вида «ключ» — «хеш-код» и поддерживающая операции поиска, вставки и удаления элемента. Хеш-таблицы применяются с целью ускорения поиска, например, при записи текстовых полей в базе данных может рассчитываться их хеш-код, и данные могут помещаться в раздел, соответствующий этому хеш-коду. Тогда при поиске данных надо будет сначала вычислить хеш-код текста, и сразу станет известно, в каком разделе их надо искать. То есть искать надо будет не по всей базе, а только по одному её разделу, а это ускоряет поиск.
Бытовым аналогом хеширования в данном случае может служить размещение слов в словаре в алфавитном порядке. Первая буква слова является его хеш-кодом, и при поиске просматривается не весь словарь, а только слова, начинающиеся на нужную букву.
Поэтому предлагаемый способ представляет собой вариант хеш-функции, которых существует не одна, отличающийся более широкими возможностями ассоциативного доступа к данным и требуемый объем перекодировочного массива из длинных чисел в удобоваримые адреса является ничтожным по сравнению с хеш-таблицами
Вопрос (уже заданный раньше) не в этом. Посчитать то можно, вопрос что дальше с результатом расчета делать и зачем он нужен. Ответа пока что не вижу.
А тут много вариантов, начиная с применения в качестве еще одного варианта хеш-функции в стандартном поиске без прочих новаций. С ними надо просто поэкспериментировать
В элементарном поиске символьных последовательностей (который мы и обсуждаем) это не применяется. Это навороты на совсем других уровнях.
Применяется, включая учет фонетики. Но, действительно, фиг ней с ружьей, это тоже лучше оставить для экспериментов
А, так это просто символьное обозначение ролика?
В символьный формат оно переводится для визуализации
Вот именно. Я то все время ориентируюсь на хеширование с преобразованием текста в уникальное длинное целое двоичное число, которое для использования в HTML, переводится в цепочку символов
Это локально немного не по теме, но в целом все-таки вполне по теме. Потому как длина этого числа, если считать его по твоей формуле, непосредственно зависит от количества символов в применяемом базовом алфавите.
Вот, кстати, сколько нужно двоичных битов, чтобы записать слово "Шарпер" по твоей формуле? Причем отдельно: сколько их нужно, если мы исходим из 33 букв в алфавите и сколько, если из 256?
А тут много вариантов, начиная с применения в качестве еще одного варианта хеш-функции в стандартном поиске без прочих новаций
Не надо много вариантов, давай для обсуждения зафиксируем ровно один.
Вопросы те же. Что делать с полученным числом? Где и в каком виде они хранятся?
Это локально немного не по теме, но в целом все-таки вполне по теме. Потому как длина этого числа, если считать его по твоей формуле, непосредственно зависит от количества символов в применяемом базовом алфавите.
Длина применяемых хешей зависит от алгоритма и доходит до 256 битов, т.е. 32 байтов (!). Большая часть результатов полученных вычислением уложится в эти байты.
Вот, кстати, сколько нужно двоичных битов, чтобы записать слово "Шарпер" по твоей формуле? Причем отдельно: сколько их нужно, если мы исходим из 33 букв в алфавите и сколько, если из 256?
С учетом того, что слов не более миллиона (с трехкратным, если не больше, запасом) то 20 бит достаточно на их перечисление в таблице соответствий. Со словосочетаниями разберемся позже
Не надо много вариантов, давай для обсуждения зафиксируем ровно один.
Легко. Можно остановиться на том, что мы предложили еще одну хеш-функцию преобразующую слова в уникальный код. Кстати мне непонятно, почему этот способ не применяется, а применяются те, что вызывают коллизии
Вопросы те же. Что делать с полученным числом? Где и в каком виде они хранятся?
В короткой хеш-таблице преобразующей длинные значения в их короткие порядковые номера.
я с Лукомором досчитал до 512.
С Лукомором - до 256...
И до 512 - без Лукомора.
Если бы Лукомор не натянул поводья - бегемот легко доскакал бы до 2 048...
С Лукомором - до 256...
И до 512 - без Лукомора.
*ехидно*
Просто Шарпер беззнаковый.
В короткой хеш-таблице преобразующей длинные значения в их короткие порядковые номера.
Или даже не в табдице, а еще в одной формуле...
Если взять логарифм от вычисленной по-Шарперу хеш-функции, даже с небольшой точностью,
он даст уникальное значение, которое не нужно хранить в короткой хеш-таблице, а можно очень просто вычислять.
А можно перейти от примитивной цифровой формы хранения адреса ячейки, к более продвинутой - аналоговой,
Короче (анонс!),
Шарпи, следи внимательно за темой про аналогового дружочка, там этот пассаж займет свое законное место,
при переходе от примитивных импульсных цифровых номеронабирателей, к аналоговым кнопочным номеронабирателям по стандарту DTMF.
можно перейти от примитивной цифровой формы хранения адреса ячейки, к более продвинутой - аналоговой
ЧМ-сигнал, в принципе, подойдёт для передачи нескольких символов сразу
Просто Шарпер беззнаковый.
Сдвинутый влево
Если взять логарифм от вычисленной по-Шарперу хеш-функции, даже с небольшой точностью,
он даст уникальное значение, которое не нужно хранить в короткой хеш-таблице, а можно очень просто вычислять.
Это ты взятие логарифма простым называешь? Проще таблиц с предвычисленными значениями ничего не бывает.
Но пример ты приведи, а то бестолковка туго варит и в чем прикол я пока не въехал.
А можно перейти от примитивной цифровой формы хранения адреса ячейки, к более продвинутой - аналоговой,
Это ваще как? У нас комп цифровой
Шарпи, следи внимательно
Как ты меня назвал???? Шарпер - генератор ультракоротких импульсов, или как вариант - шулер. Ник придуман на мембране для троллинга особо продвинутых, кои считали, что я бахвалюсь остротой ума и сообразительности. 
Вы здесь » Амальгама » Reductor Sapiens » Новая теория памяти – прорыв или утопия? #2

