.
Отредактировано Шарпер (2021-12-04 22:51:04)




Амальгама |
Привет, Гость! Войдите или зарегистрируйтесь.
Вы здесь » Амальгама » Reductor Sapiens » Новая теория памяти – прорыв или утопия? #2

.
Отредактировано Шарпер (2021-12-04 22:51:04)

Что как выяснилось запросто вычисляется...
Даже и вычислять не надо.
Это будет просто код ASCII символа, поступающего на вход.
В 1973 я закончил школу, а в 1977 заболел программированием прочитав Кларенса Джермейна, Д.Кнута, Дейкстру, Вирта и Винценбаума.
А компьютер с ассоциативной памятью с адресацией по содержимому ячеек памяти, который ты изобретаешь,
в 1972 году уже работал...
Плэтому маршрут любого символа будет из восьми звеньев.
Ты к словам перейди. Замаял уже. Для полной таблицы смчврорв - 256 ветвлений, 33 на алфавит
И все буквы разные?
Повторений букв не будет, не?
Ну посчитай сочетания с повторами.
Даже и вычислять не надо.
Это будет просто код ASCII символа, поступающего на вход.
Откуда ты бред берешь? Ты же составлял правильные символьные таблички, двоичные точно такие же. Загар же указал на то, что я запутался в ветвлениях. Теперь ты, похоже заглючил. Вернись к символьным вариантам, тем более, что тепеоь таблицы заменены вычислением
А компьютер с ассоциативной памятью с адресацией по содержимому ячеек памяти, который ты изобретаешь,
в 1972 году уже работал...
О чем я и узнал из перечисленных книг. Особенно из Д,Кнута в томе "Сортировка и поиск"
Ты к словам перейди.
А как к ним перейти?
Ну посчитай сочетания с повторами.
Откуда повторы?
Мы же их победили?!
А как к ним перейти?
Ну ты же делал таблички для слов
Откуда повторы?
Ты о чем вообще? Сочетания считаются с повторами и без. Вот и посчитай теоретическое кол-во слов из 6 букв.
Ты же составлял правильные символьные таблички, двоичные точно такие же.
Да, составлял.
Теперь глянь на мою сегодняшнюю табличку.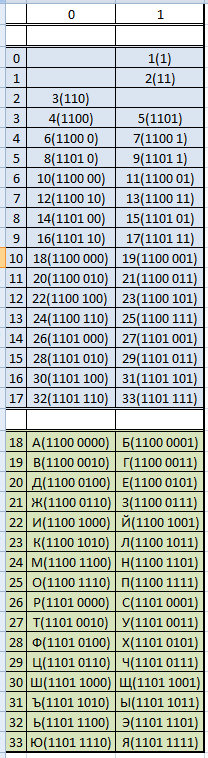
Замечательная табличка.
Все в ней правильно.
Но если откинуть верхние семнадцать строк, и оставить 16 строк нижних,
То мы увидим в них весь алфавит с соответствующими кодами ASCII символов, из которых этот алфавит состоит.
Если оргаизовать произвольный доступ по адресу, которым может быть ASCII код символа,
то будет то же самое, только памяти в два раза меньше, и поиск быстрее, потому как символы уже отсортированы по порядку адресов.
Отредактировано Лукомор (2022-01-19 15:26:35)
Сочетания считаются с повторами и без.
Нам повторы не нужны.
Сам же говорил...
Считай, не считай, букв всего 33.
Их больше не станет.
Или ты полагаешь, что в слове "колобок" три разных буквы "о"?
И у каждой буквы "о" - свой уникальный код?
Отредактировано Лукомор (2022-01-19 15:33:25)
Ну ты же делал таблички для слов
Делал, причем разными способами.
А потом понял, что не знаю, как делать их по Шарперу.
И Шарпер не знает.
Тупик!
О чем я и узнал из перечисленных книг. Особенно из Д,Кнута в томе "Сортировка и поиск"
И решил изобрести то, что они описали в своих книгах??!
Отредактировано Лукомор (2022-01-19 15:34:01)
Замечательная табличка.
Все в ней правильно.
У тебя там менингит что-ли начался? Ты же делал для простых чисел, какого черта сейчас придуриваешься? Сделай для слов
Нам повторы не нужны.
В себя приди и вспомни что речь шла о сочетаниях букв в словах
Шарпер
Шестибуквенных только больше миллиона
И все буквы разные?
Повторений букв не будет, не?
Считай, не считай, букв всего 33.
Их больше не станет.
Это о чем в контексте алфавита?
Или ты полагаешь, что в слове "колобок" три разных буквы "о"?
И у каждой буквы "о" - свой уникальный код?
В это каким боком к кол-ву сочетаний с повторениями?
И решил изобрести то, что они описали в своих книгах??!
Они описали там проблемы
Ты же делал для простых чисел, какого черта сейчас придуриваешься?
Я сделал для простых чисел, потом понял, что сделал не по Шарперу.
Переделал.
Но я не знаю, переделал ли я ее под правила Шарпера.
То-есть, я разучился рисовать эти таблички. 
речь шла о сочетаниях букв в словах
Это о чем в контексте алфавита?
В это каким боком к кол-ву сочетаний с повторениями?
Это вопрос-анфас!!!
Могу только повторить вопрос:
Три буквы "о" в слове колобок - разные символы, или одинаковые.
У них разные коды или одинаковые?
Отредактировано Лукомор (2022-01-19 16:17:59)
Я сделал для простых чисел, потом понял, что сделал не по Шарперу.
Все ты правильно сделал, а я заглючил. Разобралтсь уже
Это вопрос-анфас!!!
Могу только повторить вопрос:
А не надо повторять чушь, надо вспомнить о чем была речь и не путать методику расчета кол-ва сочетаний (с повторами или без) с алгоритмом ассоциативного поиска

Вот и посчитай теоретическое кол-во слов из 6 букв.
256^6= до хрена. Двести с чем-то триллионов.
Ну в принципе, ты верно написал, что больше миллиона.
А со словами все как-то совсем плохо. Это в буквах 33 ветвления на символ (если ограничить фантазию исключительно русскими буквами, что уже рушит задачу), а в словах десятки тысяч ветвлений на каждое слово (и то, это если допустить что мы рассматириваем только слова из словаря).
Ну в принципе, ты верно написал, что больше миллиона.
Я писал об апфавите в 33 буквы для слов из 6 букв, там ~ 1100000 вариантов без повторов и ~ 276000 c повторами. А в действительности используемых слов дай бог поллимона.
Но это все не важно. Важно, что все слова однозначно и автоматически кодируются адресами перечислением и это не требует затрат памяти вовсе
А со словами все как-то совсем плохо. Это в буквах 33 ветвления на символ (если ограничить фантазию исключительно русскими буквами, что уже рушит задачу), а в словах десятки тысяч ветвлений на каждое слово (и то, это если допустить что мы рассматириваем только слова из словаря).
Совершенно не рушит. Опять вспоминаем, что применяемых слов намного меньше кол-ва возможных вариантов, причем вычисляемых, на что не тратится память. Так что все ОК.
Я писал об апфавите в 33 буквы для слов из 6 букв, там ~ 1100000 вариантов
33^6=1 291 467 969.
Впрочем, без разницы. Миллиард все равно больше миллиона
А в действительности используемых слов дай бог поллимона
Тезис о том, что в поиске используются только используемые слова, не выдерживает никакой критики. Даже на уровне телефонного справочника
Совершенно не рушит.
Хочешь используя исключительно русские буквы обсудить качество принтеров Hewlett Packard? Или творчество группы Княzz? Не получится.
Важно, что все слова однозначно и автоматически кодируются адресами перечислением и это не требует затрат памяти вовсе
Если ты где-то хранишь информацию о том, по какому адресу какое слово лежит, так это вроде адресная память и есть.
Опять вспоминаем, что применяемых слов намного меньше кол-ва возможных вариантов, причем вычисляемых, на что не тратится память.
Слов может и немного (что в общем случае не так), но возможных сочетаний этих слов очень много. Гораздо больше, чем возможных сочетаний букв в одном слове.
Для словаря пусть хотя бы 20000 слов (это немного), возможных вариантов фраз из 6 слов будет 20000^6. Я даже считать не буду сколько это, сильно много. Больше числа Авогадро.
Все ты правильно сделал, а я заглючил. Разобралтсь уже
Любопытно было бы взглянуть на разбор.
Я, например, понятия не имею, к какому выводу вы там без меня пришли...
Впрочем, это не важно.
В этой таблице есть все!
Вся сокровищница мировой литературы, включая еще не написанные шедевры всех времен и народов.
И все это теперь уместилось в семи строчках таблицы
Отредактировано Лукомор (2022-01-19 19:02:17)
33^6=1 291 467 969.
Впрочем, без разницы. Миллиард все равно больше миллиона
Сочетания считаются иначе - b!/(n-m)!*m!
Тезис о том, что в поиске используются только используемые слова, не выдерживает никакой критики. Даже на уровне телефонного справочника
Выдерживает, потому что невозможно использовать все возможные варианты. Максимум, расширят диапазон, как с автономерами.
Хочешь используя исключительно русские буквы обсудить качество принтеров Hewlett Packard? Или творчество группы Княzz? Не получится.
Да без разницы. Один черт кол-во используемых комбинаций будет меньше возможных. Даже если все алфавиты объединить
Если ты где-то хранишь информацию о том, по какому адресу какое слово лежит, так это вроде адресная память и есть.
Адрес получается преобразованием самого текста и хранить его не надо
Слов может и немного (что в общем случае не так), но возможных сочетаний этих слов очень много. Гораздо больше, чем возможных сочетаний букв в одном слове.
А сочетания слов у нас получаются в кодированном виде, где код не длиннее адреса
возможных вариантов фраз из 6 слов будет 20000^6
Это опять неверно. Сочетания повторяются и снова кодируются
Любопытно было бы взглянуть на разбор.
Нечего смотреть. Загар мне указал на мою ошибку с неучетом ветвлений, я внял и начал вспоминать, как мы учитывали, а тут осенило, что можно вычислять
Больше числа Авогадро.
Вот это как раз и есть фундаментальное заблуждение
а тут осенило, что можно вычислять
Что можно вычислять?! 
Там ноль, единица и... все...
Какие еще вычисления?
Отредактировано Лукомор (2022-01-19 20:51:06)
Вот это как раз и есть фундаментальное заблуждение
Здесь нет никакого заблуждения. Заблуждение в том, что якобы есть какие-то ограничения на комбинации символов. Их нет, система поиска в общем случае должна быть готова искать любые сочетания, без высасывания из пальца искусственных ограничений на "существующие" и "несуществующие".
Сочетания считаются иначе - b!/(n-m)!*m!
С чего вдруг? На каждой позиции слова может стоять любая из 33 букв, повторы не запрещены (нет причин их запрещать). Тут без вариантов 33^n.
Хотя это, конечно, ерунда, правильно 256^n.
Нечего смотреть. Загар мне указал на мою ошибку с неучетом ветвлений, я внял и начал вспоминать, как мы учитывали, а тут осенило, что можно вычислять
Ну так и приведи конкретный пример вычисления. А то непонятно о чем вообще речь.
Вы здесь » Амальгама » Reductor Sapiens » Новая теория памяти – прорыв или утопия? #2

