.
Отредактировано Шарпер (2021-12-04 22:51:04)




Амальгама |
Привет, Гость! Войдите или зарегистрируйтесь.
Вы здесь » Амальгама » Reductor Sapiens » Новая теория памяти – прорыв или утопия? #2

.
Отредактировано Шарпер (2021-12-04 22:51:04)
Я вообще оставляю попытки обсуждать эту тему...
Твое право, но мне интересно было бы знать почему ты так против именно названия - ассоциативная память, которое и применяется исключительно потому, что существует такое понятие с конкретным примером, что собственно и определяет применение мной этого названия. Что де касается адресации, так любая адресация ассоциативна и это опять определил еще Вирт сформулировав процедуру преобразования ключей в адреса. А мне в принципе без разницы, как назвать - главное как это работает.
Ну и дальше.
Словарик созданный по такому алгоритму исчисления маршрутов дает не только адреса строго определенные текстом, но и коды этих словоформ, ибо адрес можно считать кодом, который замечателен тем, что занимает меньше трех байтов на словоформу из чего следует, что запросто можно построить справочник общеупотребимых фраз, и фраз имеющих разный состав, но одинаковый смысл. Но, я понял, тебе это не интересно...
Уже даже и не смешно...
А что именно тебе было смешно?

А что именно тебе было смешно?
Ты не поймешь...
очему ты так против именно названия - ассоциативная память, которое и применяется исключительно потому, что существует такое понятие с конкретным примером, что собственно и определяет применение мной этого названия.
Я не против названия, которое существует, и нигде тобой не применяется, его даже в принципе невозможно применить в той схеме, которую ты описал.
Ты не поймешь...
А ты постарайся хотя бы на уровне моего терпения 
Я не против названия, которое существует, и нигде тобой не применяется, его даже в принципе невозможно применить в той схеме, которую ты описал.
Не понимаю. Я приводил цитаты, на основе которых собственно и назвал способ ассоциативным. Можно уточнить, что конкретно неприменимо к схеме поиска по ключу, который хоть убейся, но именно ассоциирован с искомыми данными?
Словарик созданный по такому алгоритму исчисления
Словарики разные бывают.
Например, англо-русский словарик.
В нем английское слово будет идентификатором или адресом, можешь назвать это ключем, а данными - русские слова, которые соответствуют этому английскому слову.
И я могу ввести английское слово, и получить данные - русское слово, или слова, которые хранятся по этому адресу.
Но можно организовать ассоциативный поиск,
который при вводе русского слова (данных), например: "коса", выдаст все английские слова (идентификаторы),
которые хранят такие данные:
- scythe
- spit
- plait
- tress
- braid.
Еще бывают толковые словари.
Они по идентификатору на русском языке, выдают данные, также на русском языке,
толкование .
Если я введу слово, такой словарь вернет мне данные, толкование, что это слово обозначает.
Но если запустить ассоциативный поиск, например, найти все слова, которые толкуются, как астрономические термины,
по идее, должны выпасть все слова, в толковании которых есть комбинация символов "в астрономии":
- астероид,
- болид
- Венера,
- галактика,
... и.т.д.
Если задать запрос "животное", выпадут :
- альпака,
- бегемот
- волк,
- гусь
... и.т.д.
Ты же создаешь словарик, больше всего похожий на орфографический, в котором идет просто перечисление слов, с правильным их правописанием.
Этим словам - идентификаторам, не поставлены в соответствие никакие данные.
Нет смысла, поэтому, говорить об ассоциативном поиске, о поиске по данным, которых в этом словарике просто нет.
В нем любой поиск будет по идентификатору, по ключу, если угодно.
Это и забавно... 
Отредактировано Лукомор (2022-01-18 15:01:47)
на основе которых собственно и назвал способ ассоциативным
С этого и надо было начинать.
Назвал, так назвал...
Неудачное название, потому что сбивает с толку даже тебя...
Ты придумал что-то ты назвал как-то, и вот уже цитаты о твоем изобретении...
Откуда?!
Кто о нем вообще знает, кроме нас немногих, кто до сих пор понять не может.
На всякий случай, к тем цитатам, которые ты приводил, твое, вот это, то что ты придумал, имеет мало отношения.
Словарики разные бывают.
Например
Ты опять попутал принцип действия с вариантами его применения. Вот например, хеширование это способ преобразования текста в ключ/код. А способов применения хэша навалом. Предложенный способ представляет собой аналог хеширования, так что привязывать его к какой-то единственной реализации задача выходящая за рамки обсуждения, а примеры служат исключительно для иллюстрации, о чем я уже плешь всем проел, хотя судя по всему без особого успеха
Ты же создаешь словарик, больше всего похожий на орфографический, в котором идет просто перечисление слов, с правильным их правописанием.
Этим словам - идентификаторам, не поставлены в соответствие никакие данные.
Это следует расценивать как издевательство или очередное непонимание? Каждой словоформе в соответствие поставлен его однозначный код=адрес. Как еще использовать этот способ зависит от задачи, а я лишь привел пример способа кодирования фраз
Неудачное название, потому что сбивает с толку даже тебя...
С чего вдруг, если ключ всегда ассоциирован с данными? Это ты опровергаешь хрестоматию и Вирта, а не я. Как ты вообще опровергнешь неизбежность ассоциирования ключа и данных?
С чего вдруг, если ключ всегда ассоциирован с данными?
Вот у тебя нет данных,, как таковых, и с чем ассоциирован ключ?
И опять же, если ключ всегда ассоциирован с данными, то чем это отличается от традиционного поиска.
Отредактировано Лукомор (2022-01-18 16:21:27)
Каждой словоформе в соответствие поставлен его однозначный код=адрес.
Да! Но никакие данные по этому адресу не хранятся.
Представь себе телефонную книгу, в которой есть только фамилии, но нет номеров телефонов.
Совсем нет!
Каждй фамилии поставлен в соответствие номер страницы и номер строки, на которой она записана.
И где тут ассоциативный поиск?
Предложенный способ представляет собой аналог хеширования
Просто хэширование.
И уже реализовано в кэш-памяти, там именно ассоциативный поиск.
Вот у тебя нет данных,, как таковых, и с чем ассоциирован ключ?
С однозначным кодом результатом преобразования ключа. Естественный хэш.
И опять же, если ключ всегда ассоциирован с данными, то чем это отличается от традиционного поиска.
Да любой поиск ассоциативный, поскольку ищешт всегда известный ключ, разница только в определениях, которые почему-то такие, какие есть. ХЗ.
Да! Но никакие данные по этому адресу не хранятся.
Как это не хранятся? Именно, что хранятся, причем в прямом виде. Второй вопрос, что реализовано может быть по-разному, но для простоты лучше считать что хранятся
Представь себе телефонную книгу, в которой есть только фамилии, но нет номеров телефонов.
Совсем нет!
Представил. Журнал по ТБ подойдет? 
Каждй фамилии поставлен в соответствие номер страницы и номер строки, на которой она записана.
И где тут ассоциативный поиск?
Ощущение такое, что ты не видел "кондуиты". Сначала список фамилий со ссылками на личные страницы, а страницы могут быть и пустыми
реализовано в кэш-памяти
Ты путаешь хэш и кэш. Это разные вещи.
Ты путаешь хэш и кэш. Это разные вещи.
Эти разные вещи иногда лежат в одном кармане...
Примерами псевдоассоциативного кэша являются кэш-память с повторным хешированием и кэш-ассоциация столбцов.
Параллельный процессор с адресацией по содержимому ( CAPP ), также известный как ассоциативный процессор,
представляет собой тип параллельного процессора, который использует принципы памяти с адресацией по содержимому (CAM).CAPP предназначены для массовых вычислений.
Синтаксическая структура их вычислительного алгоритма проста,
тогда как количество параллельных процессов может быть очень большим, ограниченным только количеством мест в CAM.Самым известным CAPP может быть STARAN , построенный в 1972 году; несколько подобных систем позже были построены в других странах.
CAPP заметно отличается от архитектуры фон Неймана или классического компьютера,
который хранит данные в ячейках, адресуемых индивидуально числовым адресом.
CAPP выполняет поток инструкций, которые обращаются к памяти на основе содержимого (сохраненных значений) ячеек памяти.
Как параллельный процессор, он воздействует одновременно на все ячейки, содержащие это содержимое. Содержимое всех соответствующих ячеек может быть изменено одновременно.Типичный CAPP может состоять из массива адресуемой по содержимому памяти фиксированной длины слова,
хранилища последовательных инструкций и компьютера общего назначения с архитектурой фон Неймана, который используется для взаимодействия с периферийными устройствами.
STARAN в индустрии информационных технологий может быть первым коммерчески доступным компьютером,
созданным на основе ассоциативной памяти .Компьютер STARAN был разработан и изготовлен компанией Goodyear Aerospace Corporation .
Это параллельный процессор с адресацией по содержимому (CAPP), тип параллельного процессора, который использует память с адресацией по содержимому .STARAN - это процессор с несколькими массивами данных с одной инструкцией и компьютером с 4x256 1-битными элементами обработки (PE).
Машины STARAN стали доступны в 1972 году.Позже Goodyear Aerospace разработала MPP на основе аналогичных принципов, но с более крупным и широким набором процессоров.
Отредактировано Лукомор (2022-01-19 00:01:41)
Короче, если из таблицы ASCII кодов аккуратно выписать все ASCII коды символов,
и составить таблицу побитовых маршрутов, то получится снова таблица ASCII: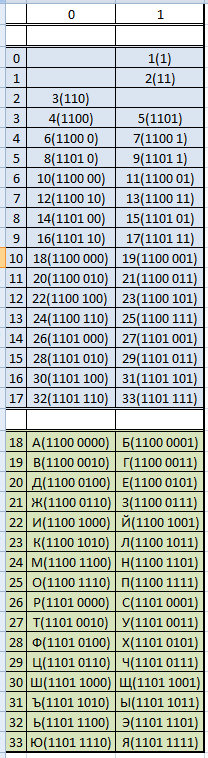
Я здесь представил только кусочек полной таблицы, только побитовые маршруты, соответствующие прописным кириллическим буквам.
Остальные маршруты строятся аналогично.
Тогда в этой таблице будет код любого символа, который может быть представлен кодом ASCII.
Также в таблице будет любой маршрут, который приведет к любому символу ASCII.
Такой вид таблицы будет окончательным, и в ней будут все символы кода ASCII, расположенные в их естественном порядке.
Теперь, пусть на вход поступил символ "Т".
Пройдя по маршруту:
(0,1) -> ((1,2) -> (2,0) -> (3,1) -> (5,0) -> (8,0) -> (14,1) -> (27,0), мы попадем в ту ячейку памяти,
где хранится символ "Т", представленный его ASCII кодом.
Таким образом, мы убедимся, что символ "Т" присутствует в полной таблице ASCII кодов, которую мы сохранили в памяти компьютера.
Поскольку таблица полная, и в ней уже есть все символы, то ничего в память дописывать после прихода любого символа не надо.
Там уже все есть.
Мы получили мощный инструмент, позволяющий убедиться, что в таблице ASCII кодов есть любой символ, который мы вводим
в виде ASCII кода этого символа.
"Да, но... зачем же?"
Отредактировано Лукомор (2022-01-19 10:58:10)
Эти разные вещи иногда лежат в одном кармане...
Но запросто существуют и независимо друг от друга. А использовать хеширование для кэша не возбраняется
Самым известным CAPP может быть STARAN , построенный в 1972 году; несколько подобных систем позже были построены в других странах.
И? В 1973 я закончил школу, а в 1977 заболел программированием прочитав Кларенса Джермейна, Д.Кнута, Дейкстру, Вирта и Винценбаума.
Короче, если из таблицы ASCII кодов аккуратно выписать все ASCII коды символов,
и составить таблицу побитовых маршрутов, то получится снова таблица ASCII:
Еще бы было не так, если сама идея маршрутов не возникла на основе совпадения кода/номера символа с номером его места! Штука в том, что для слов/последовательностей символов
такую комбинаторную таблицу почему-то постеснялись создать. Хотя м.б. это я не могу найти, но надеюсь, что просто не опустили руки, посчитав теоретическое число возможных, а не реально используемых комбинаций.
"Да, но... зачем же?"
Для перечисления словоформ (как пример!), а затем фраз и текстов в задаче разлмчения смысла, (например). Заметь, мы получаем аналог ASCII для длинных цепочек
такую комбинаторную таблицу почему-то постеснялись создать.
Ищи лучше!
Называется "Таблица кодов ASCII".
посчитав теоретическое число возможных, а не реально используемых комбинаций.
2^8 = 256.
Теоретически возможное число комбинаций кода ASCII.
И они все перечислены в таблице кода ASCII.
Отредактировано Лукомор (2022-01-19 12:17:49)
Заметь, мы получаем аналог ASCII для длинных цепочек
Эти длинные цепочки состоят все из тех же 256 символов кода ASCII.
Ничего нового там не будет.
Пройдя сколь угодно длинный маршрут, мы убедимся, что пришли в какую либо ячейку, соответствующую одному из символов кода ASCII.
Теоретически возможное число комбинаций кода ASCII.
Ты на алфавит пересчитай.
Эти длинные цепочки состоят все из тех же 256 символов кода ASCII.
Ничего нового там не будет.
Там кол-во комбинаций несколько больше. Шестибуквенных только больше миллиона, а уж словосчетаний вовсе несчитано. А нашим методом перечисляется автоматически, причем только применяемые
Пройдя сколь угодно длинный маршрут, мы убедимся, что пришли в какую либо ячейку, соответствующую одному из символов кода ASCII.
Эта ячейка имеет уникальный адрес, он же код слова/цепочки/маршрута. Вот его и рассматривай - содержимое не важно.
Вот его и рассматривай - содержимое не важно.
Я тебе больше скажу, нет никакого содержимого.
оно не только не важно, но и не нужно.
Вся информация все равно хранится в маршруте.
Поэтому содержимое аьсолютно всех ячеек - одинаковое.
Они пустые.
Даже если все овердохрена уникальных маршрутов замкнуть на одну и ту же ячейку, ничего не изменится.
Эта ячейка будет иметь уникальный адрес, он же код слова/цепочки/ маршрута.
Просто код для одного маршрута будет один, для следующего маршрута - другой.
А ячейка - одна и та же.
Отредактировано Лукомор (2022-01-19 13:52:44)
Просто код для одного маршрута будет один, для следующего маршрута - другой.
Что как выяснилось запросто вычисляется...
Ты на алфавит пересчитай.
Я посчитал Весь латинский алфавит, весь русский алфавит, все знаки препинания, все служебные команды.
Все равно код ASCII - восьмибитный.
Плэтому маршрут любого символа будет из восьми звеньев.
Шестибуквенных только больше миллиона
И все буквы разные?
Повторений букв не будет, не?
Вы здесь » Амальгама » Reductor Sapiens » Новая теория памяти – прорыв или утопия? #2

